Улучшаем звук нейросети
Сегодня стали популярны в сети сервисы озвучивания текста голосом нейросети, притом есть даже бесплатные сервисы, где голос умышленно ухудшают, чтобы люди платили деньги, да и платные тоже голоса, иногда стоит подправить, придать нужную индивидуальность. Для этого можно воспользоваться бесплатным аудио редактором Audacity, который можно скачать по ссылке https://www.audacityteam.org/download/.
Для примера буду использовать сервис, которым сам пользуюсь https://texttospeech.ru , ниже показан пример текста с использованием бесплатного голоса (Ермилов).
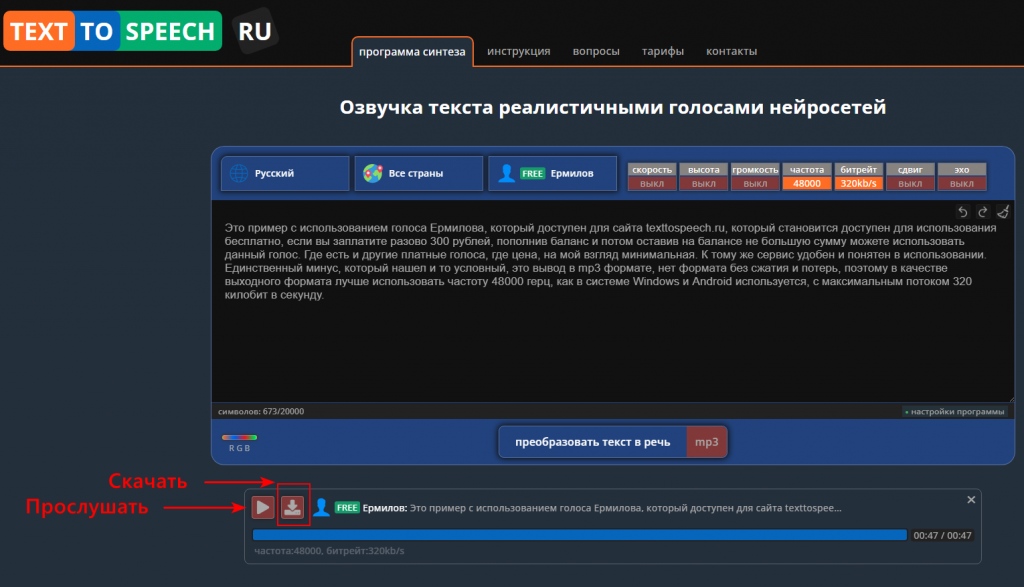
Скачиваю полученный результат, ниже его можно прослушать, где слышно, что голос гундосит, не разборчивый, хотя имеет приятную в целом дикцию. Налицо, что голос умышленно ухудшен и поэтому попробую его улучшить.
Открываю аудиоредактор Audacity и загружаю в него скаченный файл, просто кидаю его в поле аудиоредактора. И первое, что делаю, это применяю эквализацию. При этом первоначально нужно выделить аудиофаил, нажимая Ctrl+A.
И делаю кривую, как показано ниже на рис.3.
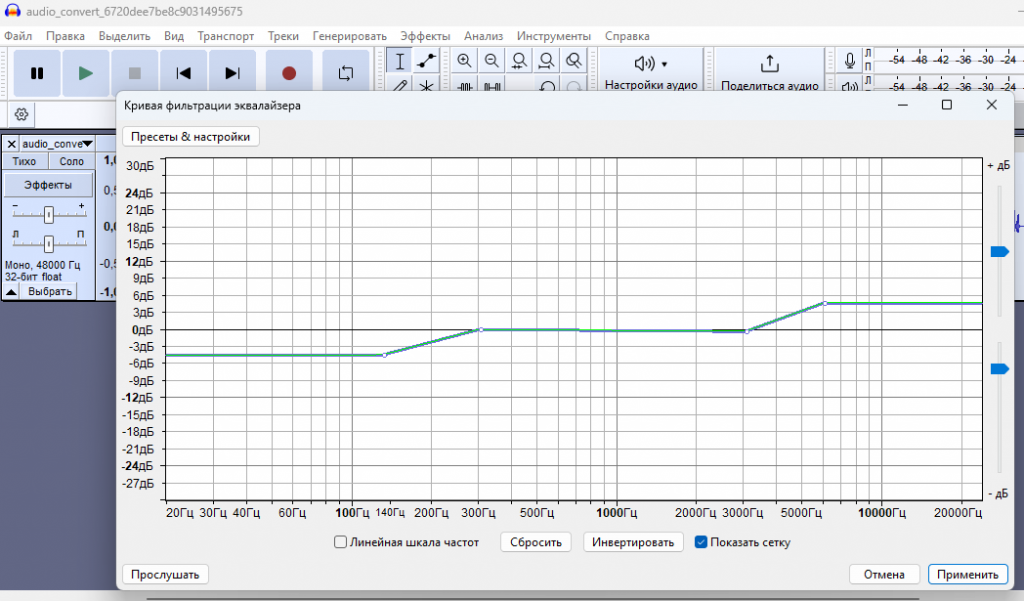
И нажимаем применить. Мы видим по виду графика, что амплитуда колеабний звука уменьшилась, так как в звуке было много низких частот, которые мы опустили и подняли высокие, а средние оставили не тронутые от 300 до 3 кГц. Поэтому, если послушаем, то заметим, что в голосе стало много шумов, поэтому нужно сделать шумоподавление. Это делается, как показано ниже на рис.4.
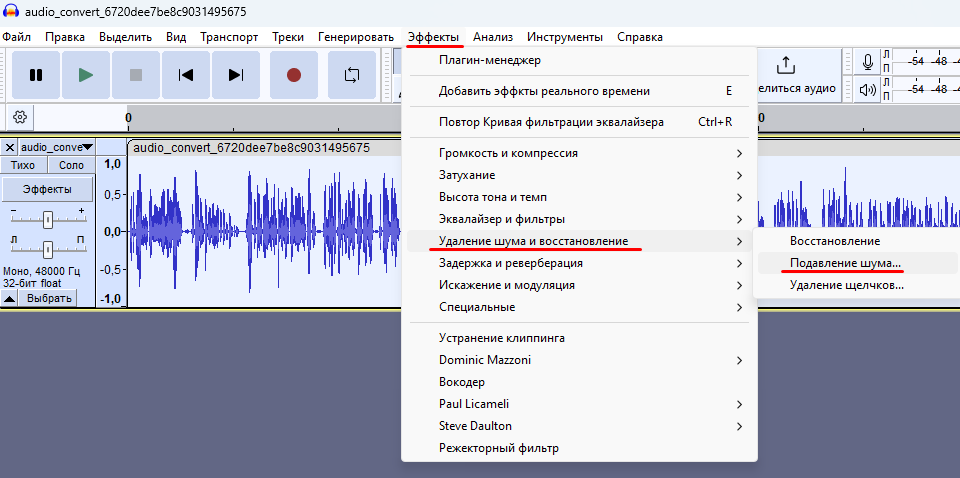
Причем это нужно будет сделать повторно, сначала выбрав «Получить профиль шума» как ниже показано, чтобы показать программе, где вам нужно шум уменьшить, в нашем случае по всему файлу, поэтому просто второй раз открываем по рис.4, потому как файл у нас весь остается выделен (он подсвечен) и применяем шумоподавление.
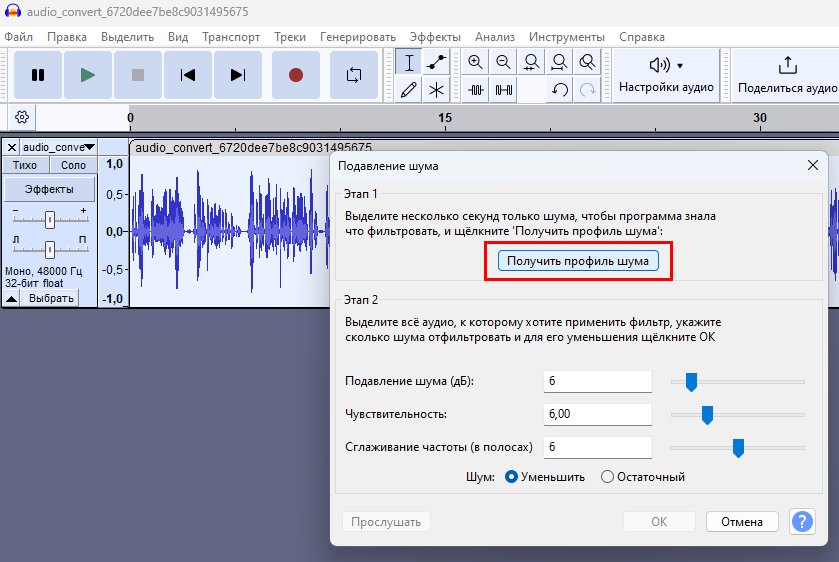
При этом в аудио редакторе мы опять видим, что амплитуда звука упала, так как шумоподавление обрезало пики.
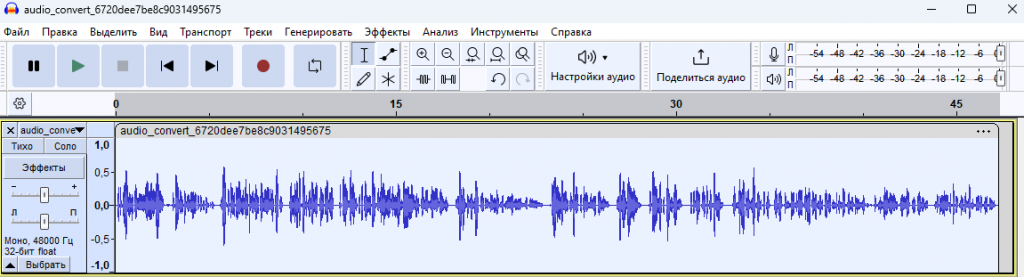
Поэтому нам нужно поднять уровень громкости, но лучше это сделать через компрессор, усилив тихие звуки, потому как данный голос несколько приглушенный. Это делается, как показано ниже на рис.7.
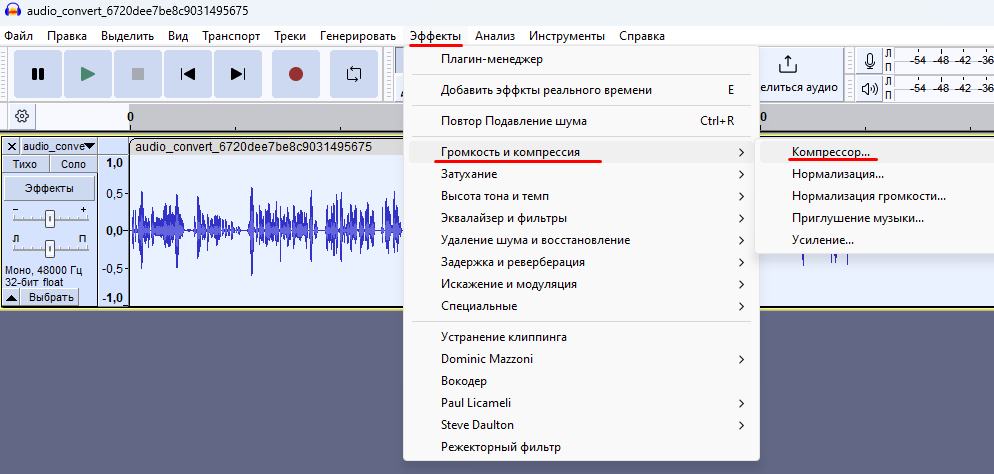
Настройки компрессора делаю -3 дБ, не сильно звук компрессируя, но можно и больше, по своему вкусу накинуть, например — 6 дБ выставить в первой строке настроек. И кроме того, по моему лучше получается, если сначала делать компрессию после эквалайзера (-6 дБ), а потом шумоподавление использовать, а затем нормализацию.
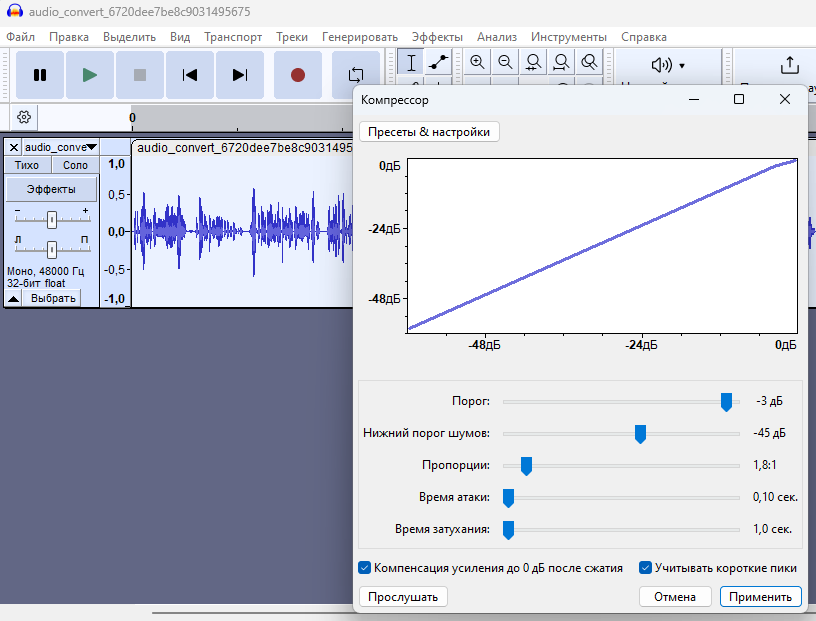
Ну и окончательно нужно вписать звук максимально в диапазон, т.е. сделать нормализацию, это делается, как показано ниже на рис.9.
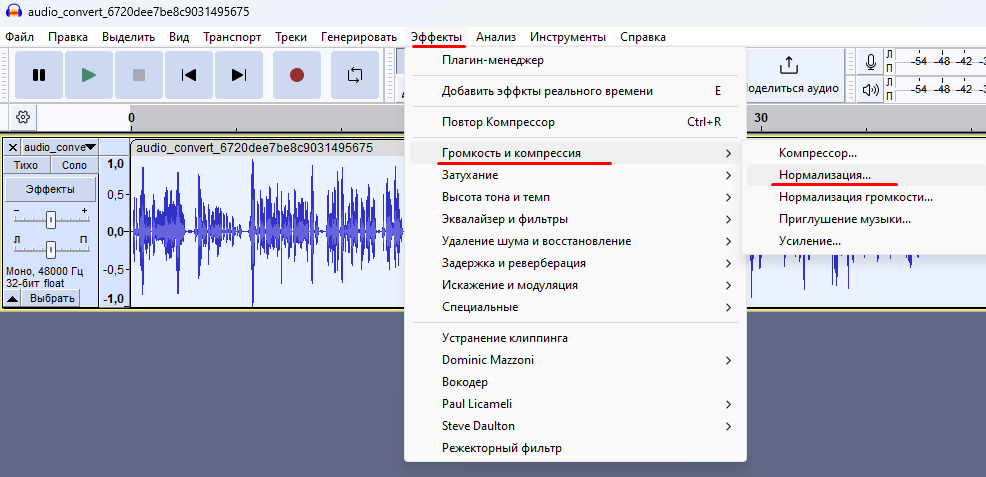
Где выставляю значение 0 дБ, т.е. по максимуму, чтобы самый большой пик упирался в самый верх диапазона записи.

Можем прослушать результат сразу же в аудиордеакторе. И если всё устраивает сохраняем Файл- Экспорт аудио, где выбираем wav формат, чтобы без деградации сигнала.
И вот что поучилось в итоге, если сравнить с тем, что было, то мне думается, что стало лучше.
Для других голосов, например для платного голоса «Владимир» применяю эквалайзер, где поднимаю НЧ и ВЧ одновременно около +4,5 дБ и поднимаю высоту тона на 2,46 процентов, чтобы голос был легче, не такой тяжелый, но это все по вкусу, кому как нравится. Для платных голосов особенно правки большой не требуется, в основном обработка требуется для бесплатного голоса.
Замечание! Нужно учитывать, что на YouTube звук несколько смягчается, если на этом сайте звук звучит без изменений, то на YouTube он ещё перекодируется в аудио кодек Opus (FullHD) и AAC(HD). И по этой же причине видео в видеоредакторе лучше сразу делать в аудиокодеке ААС или если есть, применять готовую настройку для YouTube, где это учитывается, чтобы лишнюю трансформацию звука не делать, не ухудшать качество звука.